Jul 18, 2024
Introducing Guardrails Server

We're beyond excited to announce the latest release of Guardrails with an industry-leading Guardrails Server and many more new features.
A Focus on Deployment Ready Guardrails
As more teams deploy Guardrails in production, we wanted to make it easier than ever to use Guardrails for safeguarding LLMs. Key highlights of this release that enable deployment-ready Guardrails are:
Guardrails Server to provide API-access to guarded LLMs
OpenAI SDK compatible endpoint for accessing Guardrails
Cross-language support for running Guards
Guardrails
watchfor cli-based monitoring or guardrail executionJSON generation for open source Huggingface models via constrained decoding
(In Preview) Hosted models for ML-based guardrails
Guardrails Server
This is by far the most asked for feature by all our users. Guardrails Server has a host of benefits, including:
Easy Cloud Deployment: With the new client-server model, you can take the Guards you're running on your local server and dockerize/deploy them on the cloud. We have docs, a sample repo for dockerization and a cookbook for deploying on AWS. Cookbooks on deploying to GCP and Azure coming soon!
OpenAI SDK Compatible Endpoint: Guardrails Server is available via an OpenAI SDK compatible endpoint. If you're using OpenAI or popular LLM routers such as litellm, portkey, etc., then you can access a Guard-ed LLM endpoint via a single line substitution. More docs on how to use this are available here.
Cross Language Compatibility: Since the Guards now run on their own servers, the OpenAI-compatible endpoint can be used on the client in any language where the OpenAI SDK is available.
You can run guardrails create followed by guardrails start to start running a guardrails server on localhost that you can talk to from any client. Docs on how to spin up Guardrails Server are available here.
Guardrails Watch and Telemetry Updates
Running guardrails watch on the command line allows you to observe your guardrails in real time and get detailed information about the latency, span and validation outcome of any guardrails running on a guard. Read more about how to use the new watch functionality here.
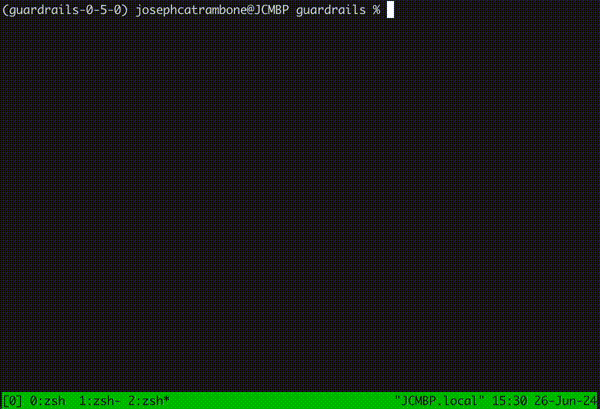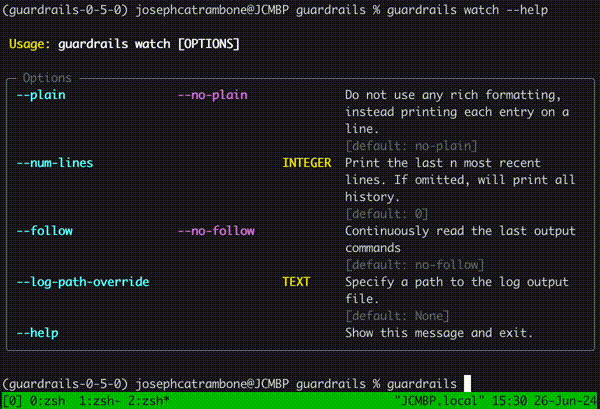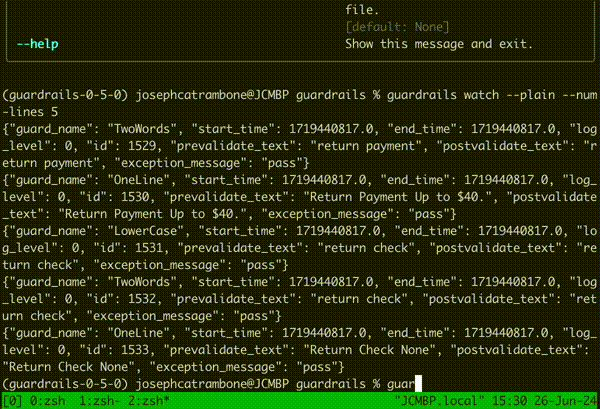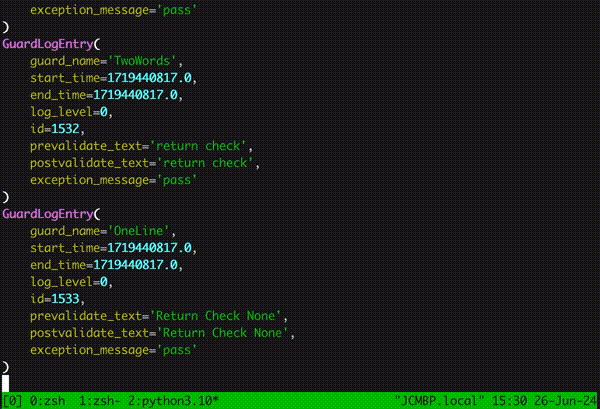
Additionally, we've introduced API-level metrics that can be toggled to talk to your OpenTelemetry OTLP collector (arize, grafana, splunk, new relic, datadog, etc all have endpoints for this). To get more information on what metrics are collected and how to configure OTLP export, check out docs here.
JSON Generation for Open-Source LLMs
The latest Guardrails release offers support for getting JSON from open source Huggingface models. This is a major step forward in enabling Guardrails to be used with any LLM, not just closed-source models. The JSON generation is done via constrained decoding, which we implement using jsonformer. More information on how to use this feature is available here.
(In Preview) Hosted Models for Model-Based Guardrails
Guardrails now has preview inference endpoints for our most popular validators. These endpoints have sub-second latency, and help you do things like check for profanity, PII, toxicity, gibberish, and more for free. Setup only requires a single opt in during configuration or hub installation. To read more about how to use hosted models, read the documentation here.
Instructions on how to self-host these models so that they're compatible with validators is coming soon!
Support Our Work
You can start using the latest Guardrails release today by installing Guardrails:
If you enjoy the work we do, you can leave
Join our Discord community: https://discord.gg/U9RKkZSBgx
Star the Github Repo: https://github.com/guardrails-ai/guardrails
Sign up for Guardrails Hub: https://hub.guardrailsai.com/
We're always looking for motivated contributors. If you're interested in contributing to the project, check out the list of open issues: https://github.com/guardrails-ai/guardrails/issues