Oct 26, 2023
How to Generate Synthetic Structured Data with Cohere

Introduction
Generating synthetic structured data is critical for training your AI models. But getting AI engines to produce structured data isn't always easy. This article will show how you can easily use Cohere and Guardrails to produce synthetic structured data.
What is synthetic structured data?
Structured data is any data put into a format that machines can easily parse, manage, and analyze.
Structured data abounds in traditional applications. Database tables, XML files, and JSON files are common examples of structured data software developers use daily. Structured data is also a good way for models in a complex AI-based application to exchange data.
Synthetic data is fictional data that is statistically or mathematically similar to real data. Companies, particularly in fields such as finance and healthcare, are increasingly using synthetic data to train their AI models. Recent research shows that, on top of being cheaper to produce, synthetic data may create AI models that are just as good, if not better, than models trained on real-world data.
Generating synthetic structured data with Cohere and Guardrails AI
Generating synthetic structured data using today's AI engines can be a challenge. By default, a Large Language Model (LLM) outputs unstructured text. So, how do you coach it to return properly structured synthetic text?
Using Cohere and Guardrails together, you can generate synthetic structured text with high realism and accuracy. Cohere's Command model provide generation capabilities for structured data. Guardrails AI adds structural and quality assurances that refine Cohere's output, resulting in more accurate, realistic data.
Let's discuss how the Cohere and Guardrails AI portions work, then see how they work even better together.
How Cohere works
Cohere offers access to cutting-edge LLMs through a simple API. It provides a variety of API endpoints to use depending on your use case, including Chat, Generate, Embed, Rerank, Semantic Search, Rerank, and Classify.
Cohere's models power a variety of use cases, including running interactive chatbots, generating text for product descriptions or blog articles, moderating content, and recognizing intent. Companies can leverage Cohere's LLMs in their apps without needing to train their own AI models from the ground up.
How Guardrails AI works
Guardrails AI is a Python package you can use to enhance the outputs of LLMs by adding structural, type, and quality assurance checks.
Guardrails AI leverages the pydantic format, one of the industry's most widely used data validation libraries. Guardrails checks for defects such as bias in generated text and bugs in generated code. Guardrails also enforces structural and type guarantees (e.g., returning proper JSON formatting) and takes corrective actions, such as prompt submission retries, when validation fails.
Creating a Guardrail for LLM output is a three-step process:
Create a data structure spec. You can create a spec either using a Pydantic model or using RAIL. RAIL (Reliable AI Markup Language) is a language-agnostic, human-readable XML dialect for defining the expected structure and type from the LLM, as well as any validators and corrective actions. For the example below, we will use Pydantic.
Create a guard from the spec. The Python
gd.Guardobject serves as the basic executable unit for calls to the LLM.Wrap the LLM call with the guard. The guard combines the spec and the call to the LLM in order to validate, structure, and correct its outputs.
Walkthrough: Generating structured data with Cohere and Guardrails AI
Now, let's see how to use these two technologies to create highly realistic synthetic structured data.
Prerequisites
Python 3 installed on a dev machine with the latest version of Pip
Cohere account and a Cohere API key
Generating data with Cohere
First, to get started with Cohere, sign up and generate an API key.
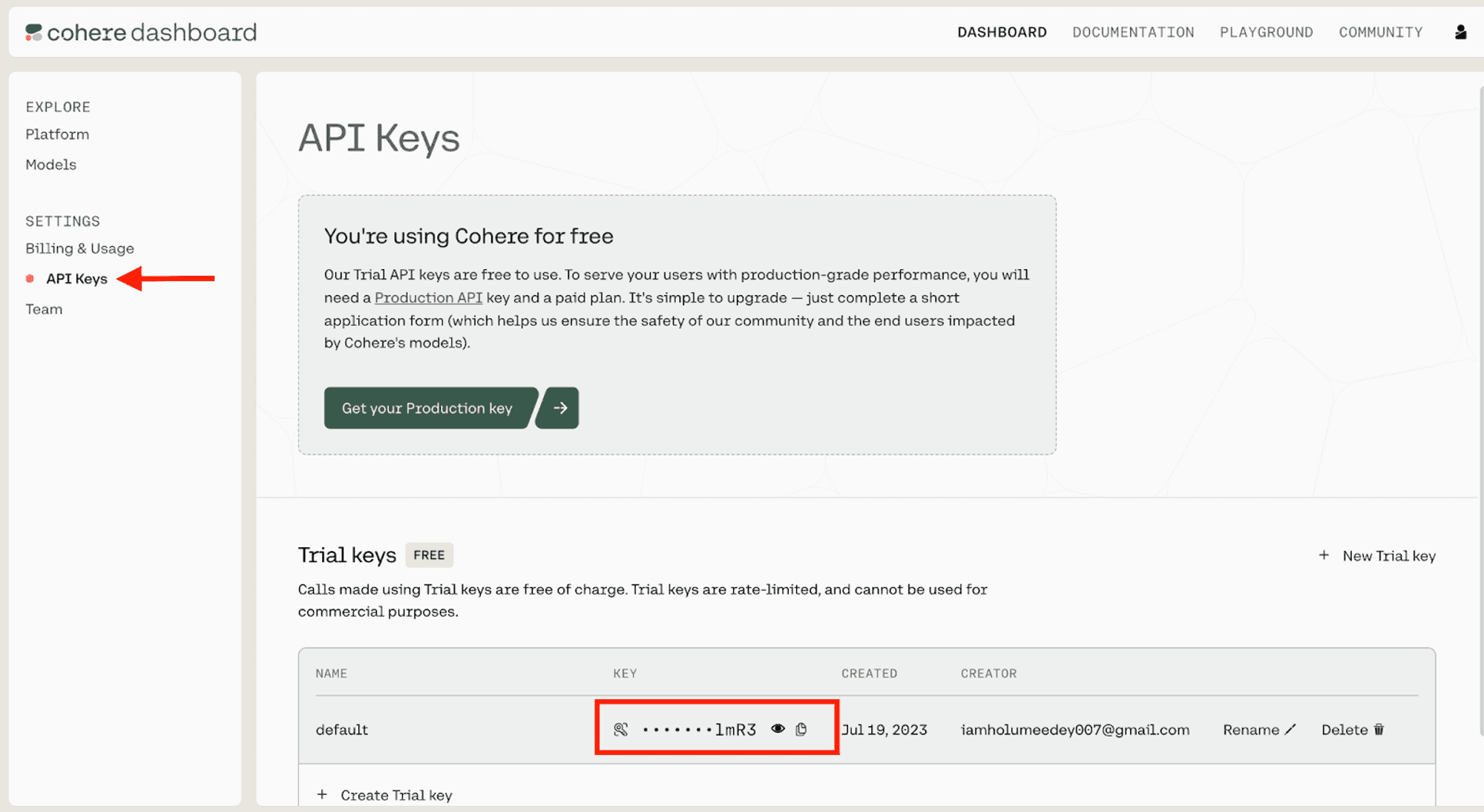
We'll use Cohere's Generate endpoint (co.generate) to generate realistic text conditioned on a given input. Cohere supports a REST API that developers can call from any programming language. In this walkthrough, we'll use Cohere's official Python SDK.
Start by installing the Python library for Cohere on your dev box:
Next, write a simple Cohere application to generate structured data in JSON format:
Let's step through this line by line to understand what's going on.
import cohere: Standard Python import call.co = cohere.Client(api_key='<API KEY>'): Create a client object named co to interact with the Cohere API. It uses the provided API key to authenticate the requests. The API key is essential for accessing the Cohere services.(Note: Remember never to check API secrets directly into source code or leave them in Notebooks! Use a secrets vault, such as AWS Secrets Manager, for secure storage and retrieval of secrets.)
response = co.generate(...): This line sends a text generation request to the Cohere API using the generate method. It provides several parameters as input for the text generation task:
model='command': Specifies the type of language model to use for text generation. In this case, it uses the "command" model.prompt='Generate different structured data and render it in JSON format': Contains the input text prompt that serves as a starting point for text generation. The language model will generate text based on this prompt.max_tokens=300: Sets the maximum number of tokens (words or subwords) the generated text should contain. This is used to limit the length of the generated response. Longer responses take more computational power to process, which increases application costs.temperature=0.9: Controls the randomness of the generated text. Higher values (e.g., 1.0) make the output more diverse, while lower values (e.g., 0.2) make it more deterministic.k=0: The number of top-k candidates to sample from during text generation. Setting it to 0 means it will consider all candidates.stop_sequences=[]: A list of strings that will stop the text generation if encountered. However, the list is empty, so the generation will continue until it reaches themax_tokenslimit.return_likelihoods='NONE': Specifies whether to return the likelihoods of each generated candidate. In this case, it is set to'NONE', meaning it won't return likelihoods.
print(response): This line prints the entire response object returned by the Cohere API after text generation. The response may contain various information, such as the generated text, the likelihoods, and other metadata.print('Prediction: {}'.format(response.generations[0].text)): This line prints the generated text obtained from the response. Theresponse.generationsattribute is a list of generated text candidates, andresponse.generations[0].textretrieves the first candidate's text. The format function includes the generated text in the output string, labeled as "Prediction."

Adding guards with Guardrails AI
Now, let's improve the quality of Cohere's response by adding a guard. Install Guardrails AI and other required dependencies locally using pip:
Create a new Jupyter Notebook entry that imports the Guardrails AI library:
We will define structured data for an online order that has the following attributes:
Each user should have a first and a last name.
Each user should have between 0 and 50 orders.
The dataset should contain exactly 10 rows.
The output should be in JSON format.
To accomplish this, we'll create a spec as a Pydantic model:
The Pydantic file above defines two models: an Order model that defines the format of each order; and an Orders model that holds a list of Order objects. The validators parameters for each property define the parameter format that the output from the LLM must satisfy for Guardrails to accept it.
Now, we can create a Guard from our Pydantic model:
Guardrails will generate a full prompt based on our Pydantic model. Note that it compiles an XML specification for the output and makes it part of the prompt.
Finally, let's wrap our call to the LLM in Cohere with our guard:
Once again, let's break this down line by line:
raw_llm_response: The raw response object returned by the GPT-3 model. It will contain various information, such as the generated text, the likelihoods, and other metadata.validated_response: The validated or processed version of the raw response.co.generate: The method to call on Cohere to generate our synthetic structured data.model="command": Specifies we could use Cohere's command module.max_tokens=1024: Again, we usemax_tokensto limit response length and cap computing resources.temperature=0: The degree of randomness. Since this is structured text, we use 0.3 to specify we want the result to be mostly deterministic.
The result in validated_response is the JSON data generated by Guardrails:
Guardrails logs the full history of calls it makes to the LLM. You can see this history in Python by running:
You can use this information for:
Debugging and pinpointing issues. Use the full sequence of LLM calls to identify the source of errors or unexpected behavior in the generated output.
Understanding model behavior. By reviewing the full history, developers can better understand how the LLM interprets and responds to various input types.
Fine-tuning and parameter optimization. The history of calls provides insights into how different prompts and parameters affect the model's responses. This information can be invaluable when fine-tuning the model or optimizing parameters to achieve desired outcomes.
Version control and collaboration. Developers can track changes and experiment with different prompt variations over time. This is essential for version control and collaboration among team members on the same project.
Context preservation. Examining past calls preserves the context of previous interactions with the model. This context is vital when dealing with conversations or dialogue-based systems, where the model's responses depend on preceding prompts.
Conclusion
Cohere combined with Guardrails AI is a novel and groundbreaking approach to data generation. In this article, we've introduced both technologies and shown how you can leverage them with a simple Python script to create your own synthetic structured data. By harnessing the power of Large Language Models, you can effortlessly generate diverse and contextually relevant structured data with just a few lines of code.