Aug 27, 2024
How we rewrote LLM Streaming to deal with validation failures

Streaming enables responsiveness in large language model applications by allowing data to be processed and transmitted in real-time, rather than waiting for an entire output to be collected and analyzed. This means that user inputs can be quickly processed and responded to, creating a seamless and interactive experience - one good example of this would be ChatGPT.
However, this presents many problems for validation. If you're looking to prevent your LLM from outputting personally identifiable information or profanity, it seems simple enough to just run validation on every chunk that comes in. However, that approach doesn't work for more context dependent validation: for example, if you're trying to check for financial tone, or politeness, or for hallucinations. For these validators, context is really important. Any given chunk on its own may or may not be polite or true, you have to look at its context to find out if it's valid or not.
Note: To learn more about streaming in Guardrails, take a look at our concepts doc.
Our old streaming architecture
To address this need for context, our old streaming architecture ran validation on the entire accumulated output so far.
Here's a simple way to think about it: As chunks A, B, and C come in, Guardrails would run validators on A, AB, and ABC.
This has the advantage of maintaining context, since you're running validation on everything you've seen from the model so far. It also maintains the primary benefit of streaming: responsiveness. If the LLM outputs something profane or untrue, the validators can catch it right as the chunk is emitted, instead of having to wait for the entire accumulated output like they'd have to in a non streaming scenario.
However, running on the entire accumulated output can get extremely expensive, both in terms of compute cost and latency. In some ways, it's also wasteful - why run validators on contents that you've already validated? The answer to that question is that validation requires context, but does it always require the entire accumulated output as context? Usually, no.
Our new streaming architecture
The key insight here is that validators require context, but that context usually doesn't have to be the entire accumulated output. Our new streaming architecture allows validators to specify exactly how much context they need - whether that's a sentence, a paragraph, or the entire output. Validators then accumulate chunks until they have enough context to run validation.
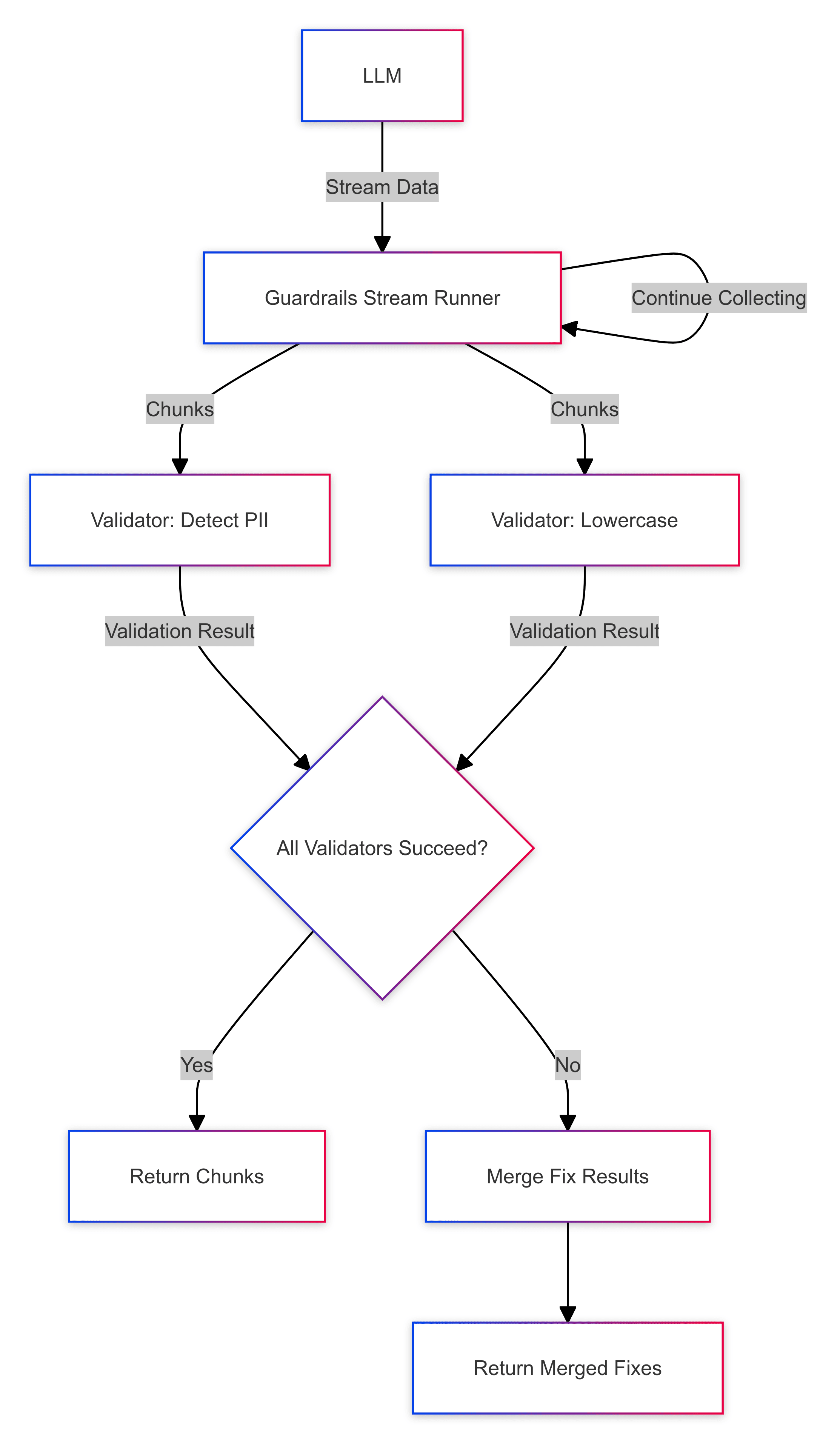
For example, say we have two validators, one that checks for personal information (PII) and one that checks for politeness. The PII validator doesn't need more than a sentence of context to make a decision, while a politeness validator might need more to handle edge cases like sarcasm. As chunks come in, each validator will wait until they've accumulated enough context before emitting a validation result.
This approach improves latency greatly, while still giving validators the context they need to give an accurate result.
Try it out
Our new streaming architecture is now live in Guardrails. It offers both robust validation and responsive streaming. Streaming is compatible with all validators, and you can see instructions to enable streaming here https://www.guardrailsai.com/docs/how_to_guides/enable_streaming.