Nov 8, 2023
Reducing Hallucinations with Provenance Guardrails

Introduction
Hallucination can be a serious issue when generating data using AI. In this article, we'll show how you can use the Guardrails AI provenance validators to reduce hallucinations for more accurate results.
The hallucination problem in AI
In our last article, we showed how to use Guardrails AI to generate more realistic synthetic structured data using a Large Language Model (LLM). Structured data is great when we need machines - e.g., different services in an application service fabric - to communicate with one another. For data displayed to humans, we generally want to generate unstructured data.
AI engines such as ChatGPT can generate unstructured text with high fidelity to real human conversations. However, when an AI engine doesn't know something, or it will sometimes generate incorrect information that seems/look like a fact due to the nature of the generated language. This can happen in both structured and unstructured data.
These hallucinations can have negative real-world consequences. Just ask the attorneys who filed court documents that included fictitious citations generated by ChatGPT.
Common strategies to address hallucinations
Solutions to the hallucination problem are still evolving. Common ways to do so today are providing more context in prompts, fine tuning, retrieval augmented generation (RAG) and even building your own models.
Retrieval augmented generation (RAG) enables LLM applications to leverage vector embeddings from source documents. It is quickly becoming the most common way to reduce hallucinations but many still face challenges despite implementing this. Guardrails AI provenance validators leverage embeeddings from RAG systems to even further improve accuracy and reduce hallucinations.
Using Guardrails AI provenance validators to automate hallucination reduction
Another way to reduce hallucinations is to use Guardrails AI. Guardrails AI provides a rich library of validators you can leverage programmatically to test that AI output meets a specific set of criteria.
Guardrails AI's provenance validators detect and limit hallucinations from LLMs that depart from the material in the supplied source documents. We provide two provenance validators, both of which can operate on either the whole text or on each sentence of the text in turn.
In the following example, we'll show how to use these validators, provenance v0 and provenance v1, to operate over a text selection on a sentence-by-sentence basis in Python. In other words, the validators will inspect each sentence for potential hallucinations and remove the parts that have no foundation in the source text.
Prerequisites
To run the code below, you'll need to do the following:
Install Python prerequisites
You can run this from Jupyter or your Python command line:
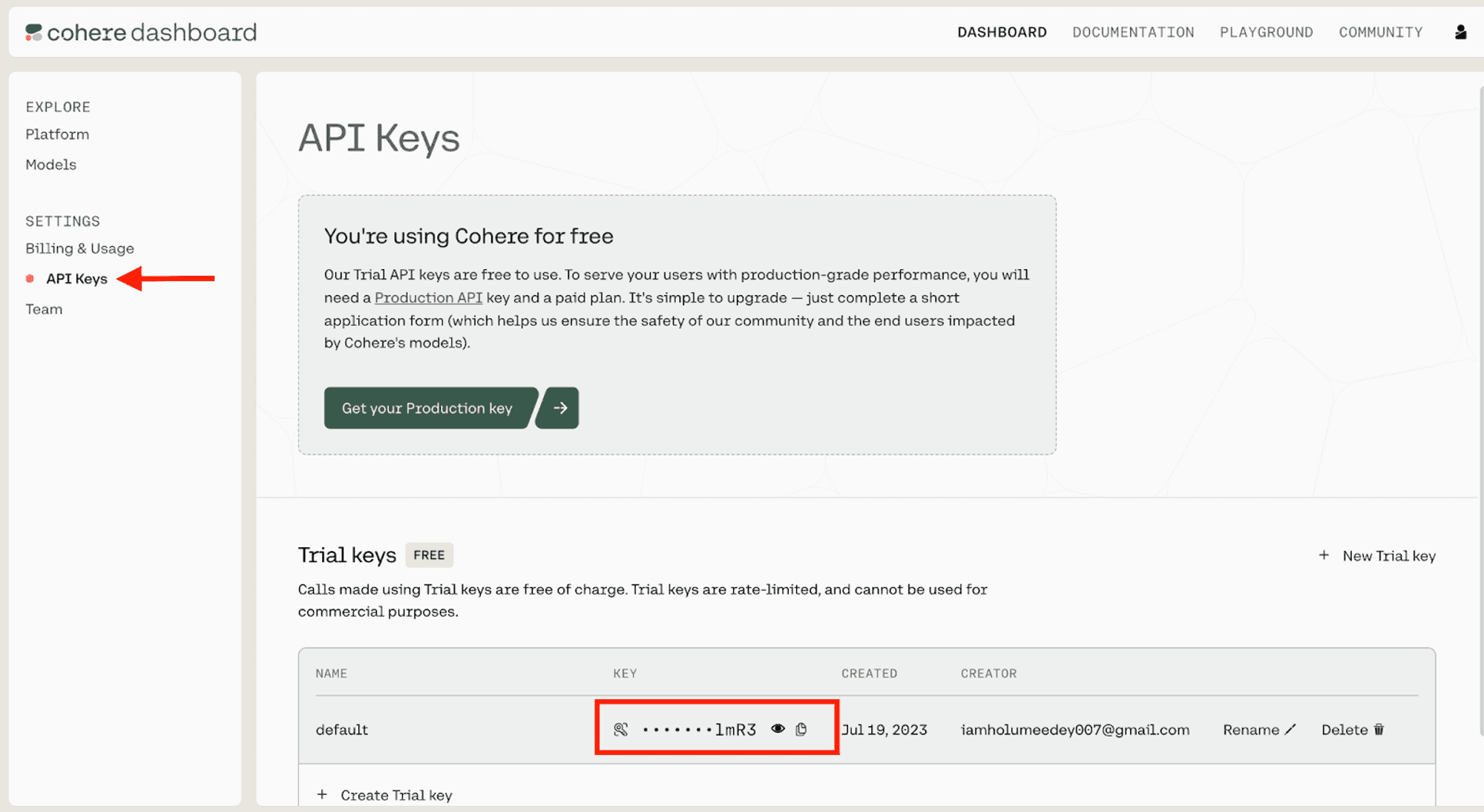
Obtain Cohere API key (Provenance v0 example)
Guardrails AI can operate against any LLM in the marketplace. In this article, we'll use both Cohere and OpenAI.
You can obtain a Cohere API key for free by signing up for a Cohere account. Once registered, from your Cohere Dashboard, go to Settings -> API Keys to request a new key.
Obtain OpenAI key (Provenance v1 example)
To obtain a free OpenAI key, create an account. When asked to choose between using ChatGPT and API, select API.

From there, select your account icon in the upper right corner and then select View API keys. Select Create new secret key to generate an API key.
Make sure to copy and save the value somewhere, as you will not be able to copy it again after this. (You can always generate a new API key if you lose the old one.)
Using provenance v0 to confirm a response is supported by the source text
First, let's see how to use provenance v0 to run sentence-by-sentence confirmation to ensure a response from an LLM is supported by the source text. In this example, we'll use Cohere's Embed model, which supports many Natural Language Processing (NLP) use cases, to compare a set of sources against previous output from another LLM.
First, we'll start with our source text, which is advice on how to litter train a cat. It's a lot of text to include in the article, so we've defined it in a GitHub Gist here. Import this into your Jupyter notebook and run it.
Next, we'll create an embed function for Cohere. This Python function will take our source above and embed it into Cohere. Embedding renders our sentences as numerical values whose values are close to one another if they are similar but far apart if they are dissimilar. They enable finding semantically similar sentences. Using embeddings supplements Cohere's training with your own data so you don't need to build your own Large Language Model from scratch.
(Make sure to replace the COHERE_API_KEY value below with your own API key. If committing source code, replace this value with a reference to a secure form of storage, such as a secrets vault.)
Note that we're only defining the function here. Before calling it, we will initialize a Guard object in Guardrails and pass it a provenance v0 validator.
For the validator, we set three values:
threshold: How sensitive we want the validator to be in detecting variance or hallucinations. In this case, we set it to 0.3, which makes it highly sensitive.validation_method: Set to sentence to examine each sentence of the checked text for accuracy.on_fail: What to do if Guardrails AI determines the LLM output is hallucinated. fix means Guardrails AI will remove the hallucinated sentences.
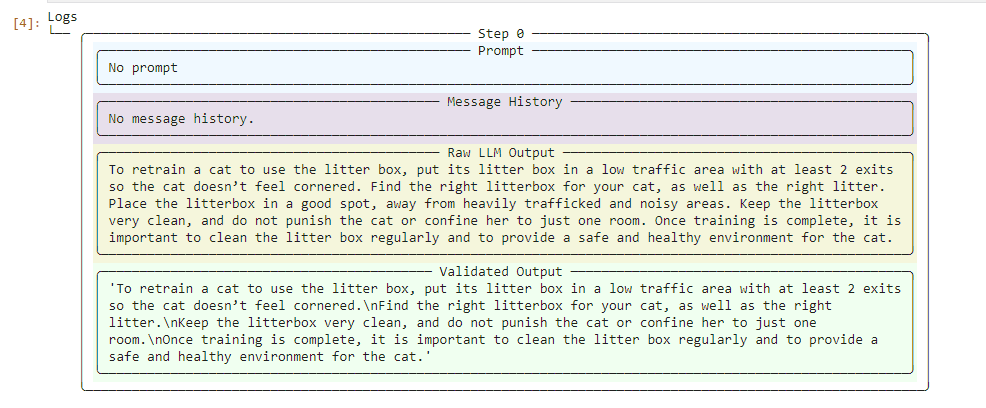
Finally, we call our Guard with the LLM output we want to check against our sources. In this case, we're supplying a chunk of text on what another LLM thinks the best way to litter train a cat is.
Guardrails AI will take this text and chunk it down into smaller units before embedding it into Cohere. Then, it will use Cohere's embeddings of our sources plus its own internal logic to determine which parts of the text are accurate and which might be hallucinated.
In this example, a good chunk of the LLM output corresponded with our source text. However, as you can see below, Guardrails AI deemed one sentence as suspect and stripped it out.
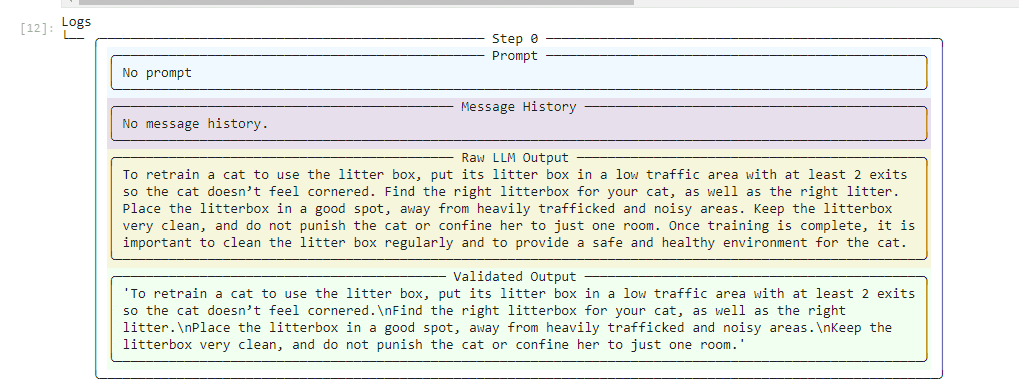
Using provenance v1 to perform LLM self-checks
The provenance v1 validator checks whether the LLM output is hallucinated by prompting a second LLM. This work similarly to the case above but with a few minor differences.
First, we initialize a provenance v1 evaluator. The llm_callable parameter here can take two types of arguments:
An OpenAI ChatCompletion model, such as
gpt-3.5-turboorgpt-4.A Python callable function that calls back to an LLM of your choice.
In the example below, we usegpt-3.5-turbo. We use atop_kvalue of 3 to determine how many of the most statistically relevant chunks we should retrieve. A low value of 3 restricts output to the most relevant chunks. The other parameters are the same as the ones we used for provenance v0.
Next, we'll call Guardrails AI's parse function as we did in the example above, passing our sources as additional context to the AI engine.
Note that we also pass an api_key method with our OpenAI key. You can omit this hard-coding by setting the environment variable OPENAI_API_KEY:
os.environ["OPENAI_API_KEY"] = "<OpenAI_API_KEY>"
Finally, we print out the result of the call:
In this example, our statements about litter training cats comport both with our source data and OpenAI's own knowledge. So the response is little changed from the other LLM's output.
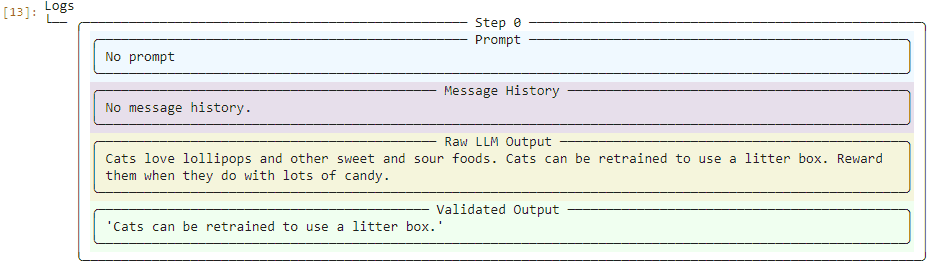
But let's see what happens when we pass in input that's not quite as accurate:
Here, whatever LLM we used previously asserts that cats can be bribed with candy. Guardrails AI flags this obvious falsehood and whittles the response down to the one statement that appears to be factual (if not very useful):
Conclusion
Hallucinations in AI output undermine user's trust in AI-powered solutions. Using Guardrails AI's provenance validators, you can leverage original sources and the power of other LLM engines to reduce inaccuracies and improve output quality.