
Custom Benchmarks
Custom Benchmarks
Build and run domain-specific benchmarks at scale—compare models or application versions on your exact scenarios and metrics.

Model & Provider Comparison
Generate identical conversation scenarios across multiple LLMs/providers. Score performance side-by-side using built-in or custom metrics for accuracy, latency, safety, and tone.
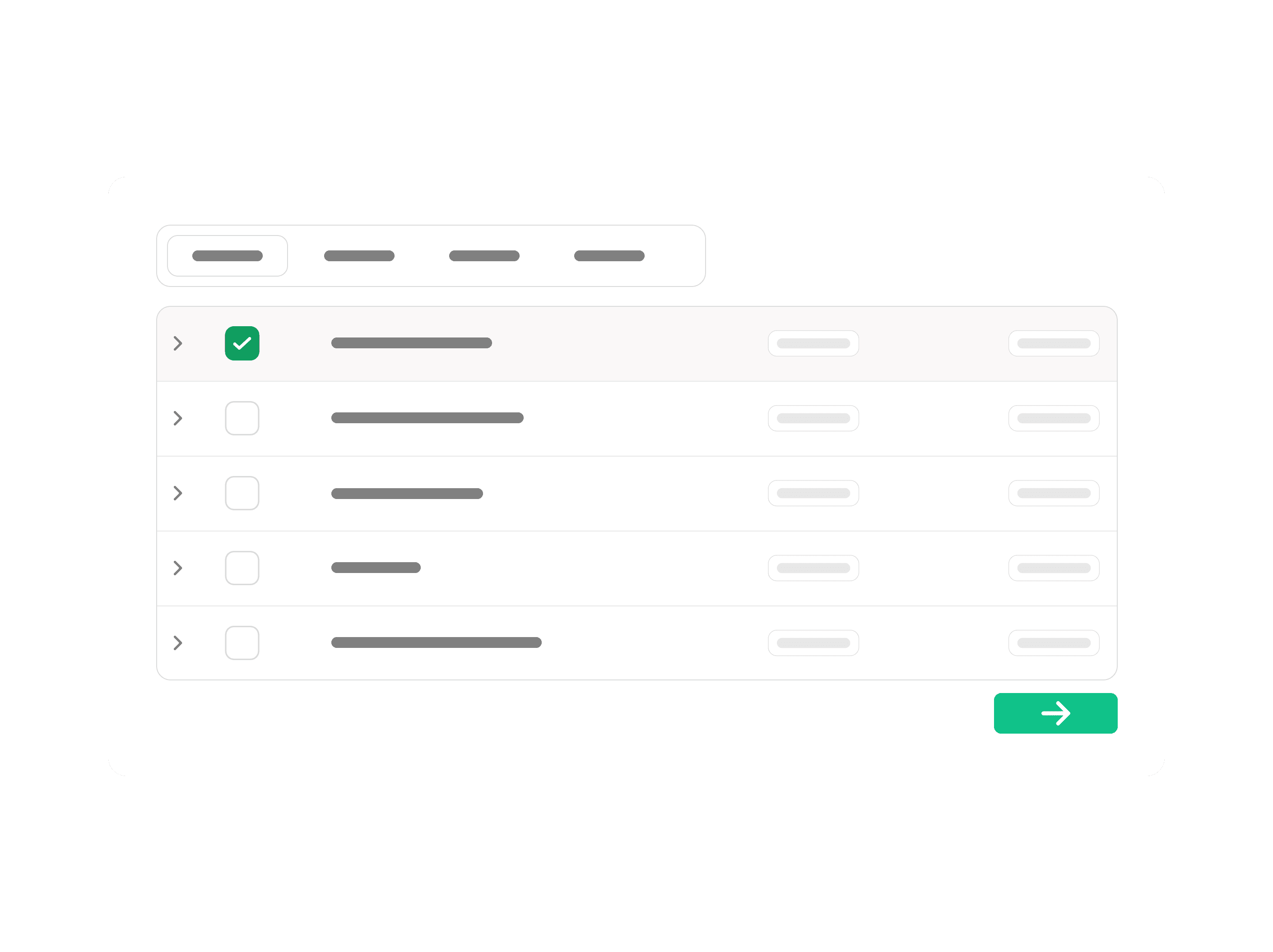
Custom Metric Benchmarks
Define your own risk or performance metrics (e.g., domain expertise, multi-turn coherence, constitution adherence). Snowglobe runs thousands of tests and aggregates results into clear benchmark reports.
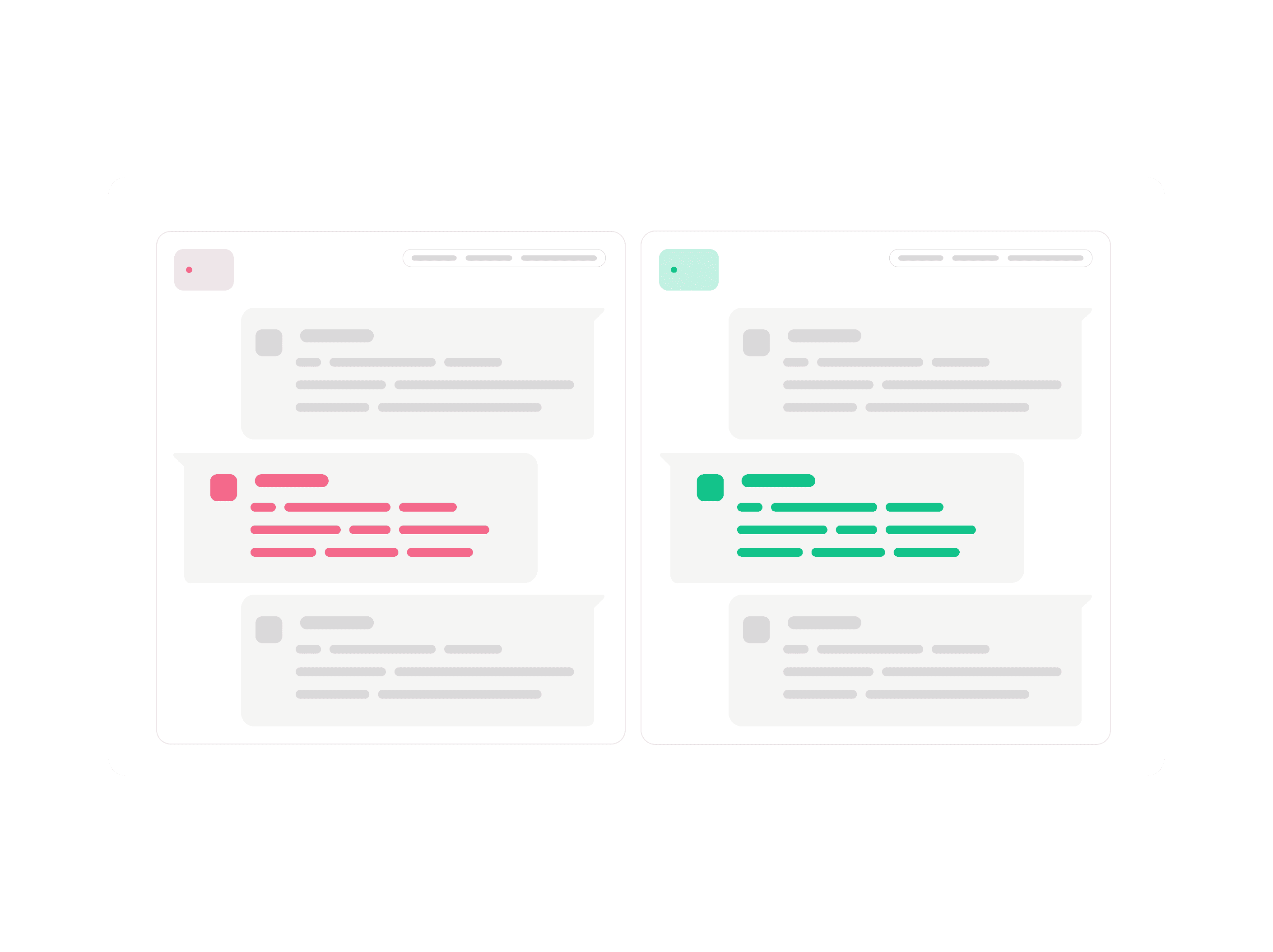
Configuration & Prompt Testing
Test prompt variations, system instructions, or tool setups. Identify which configuration holds up best on your edge cases and production-like data.
Benchmarks built for your reality
Public benchmarks don’t reflect your real use case, users, or risks. Snowglobe creates benchmarks grounded in your context.
Evaluations that don’t go stale
Standard evals are static and obsolete quickly. Snowglobe runs dynamic, adaptive benchmarks that stay fresh.
Results you can actually act on
Get actionable comparisons—raw scores, failure traces, and exportable reports with no manual aggregation.
Built for Production AI Teams
For teams building production AI systems who need evaluation data that's realistic, comprehensive, and fast.
~500 scenarios in 30 minutes
Replace weeks of manual curation with automated generation
Enterprise context grounding
Scenarios reflect your domain, terminology, and user patterns
Live system interaction
Tests adapt to actual AI responses, not assumed behavior
Multi-turn conversation support
Evaluate complex dialogue flows, not single-exchange Q&A
Programmatic edge case discovery
Systematically explore failure modes humans wouldn't think to test
Risk quantification
Move from "we tested it" to "here's our measured risk surface"