Jul 19, 2024
Latency and usability upgrades for ML-based validators

Recently, we've been working on reducing the latency of our validators. We started with validators that were using ML models.
We found that for these models, latencies running locally (on our M3 macbooks) were quite slow. This was because of a lack of Nvidia CUDA support, which is useful in optimizing model performance.
These models can also get quite heavy, and users have to wait through downloads and installations of the models.
To solve all of these problems, we attempted to host the models serving these validators on an EC2 instance with T4s. This dramatically changed our latency profiles and installation speeds.
We started with the ToxicLanguage and CompetitorCheck validators.
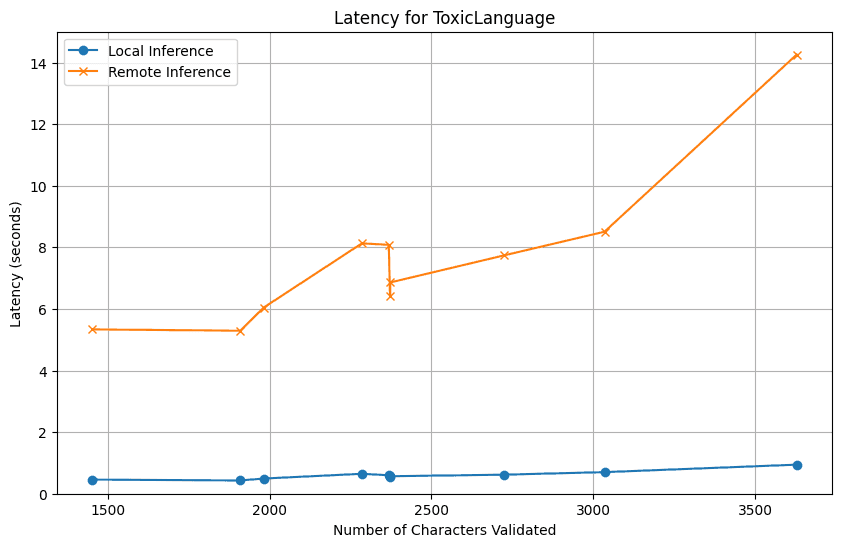
Our main objective here was to figure out how latencies for both local and remote inference change based on the number of characters of the text we want to validate.
Results
We won't bury the lead -- running with remote inferencing on T4s is way faster than our local machines.
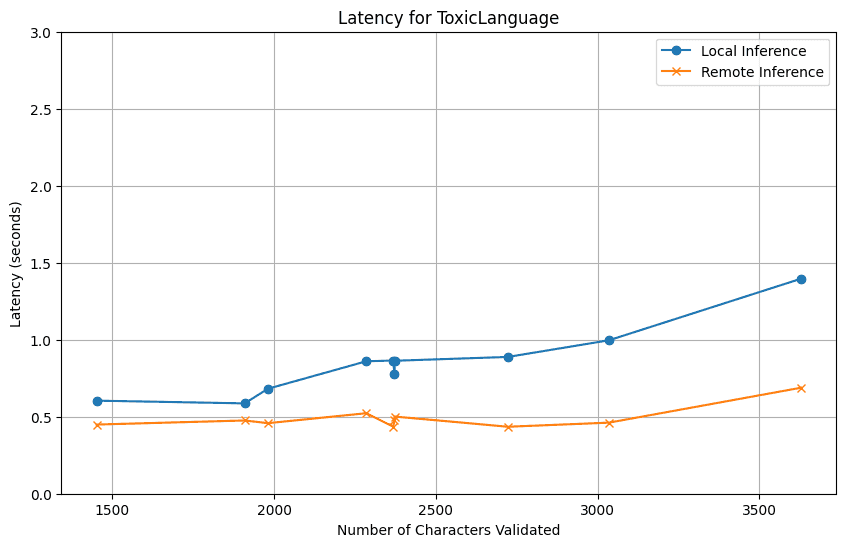
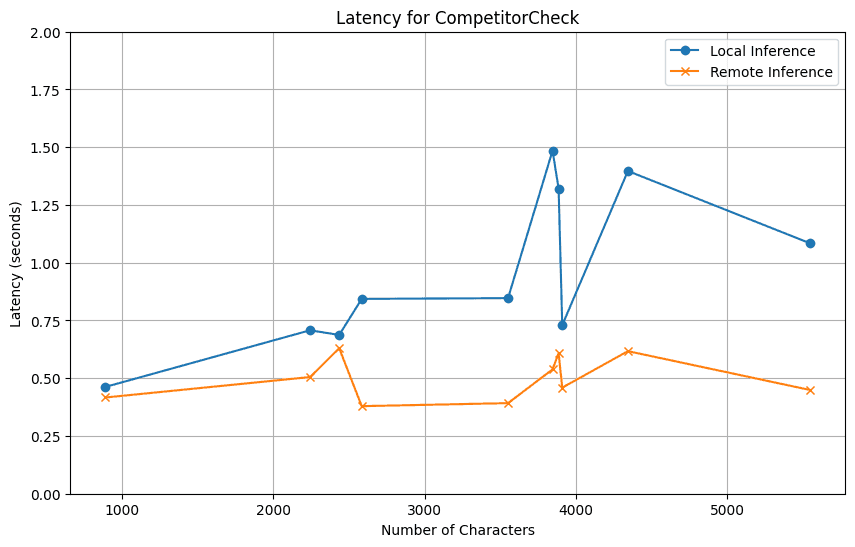
As expected, our control experiment using CPUs on the cloud ended up taking longer, due to the additional network latency.
Read on if you're interested in using this feature or want to know how we got these numbers.
Guardrails Inference Endpoints
Guardrials inference endpoints are available publicly for signed-in users. We currently have these two endpoints up, and we will follow quickly with DetectPII and RestrictToTopic. Using these inference endpoints saves you a ton of download time and makes your inferencing latencies quick.
We do not log any of your data that's sent through the validator, other than anonymized usage statistics.
Latency benchmarking
We generated benchamrks in a series of short steps
Host inference endpoints not using GPU
Host inference endpoitns using GPUs
Generate some data to test the endpoints against
Hit the endpoint using the data while timing
Hosting endpoints
We followed these instructions to set up two different endpoints, one without GPUs and one with. These endpoints use a standard interface to communicate with validators.
Generating data
We wrote a small script that asks gpt-4o-mini to generate toxic sentences (for ToxicLanguage) and text that contain names of competitors (for CompetitorCheck). This generates sentences ranging from just under 1,500 characters to approximately 3,500 characters for ToxicLanguage, and from just under 1,000 characters to around 5,000 characters for CompetitorCheck.
It's worth noting that GPT models aren't the best at returning an exact number of characters, which lead to the slight variations in the lengths of generated text.
Latency Benchmark
With our data ready and stored in a data.csv file, we set up two guards:
Local Validation Guard: this guard is set up to run the validator locally and we do this by setting the
use_localflag to True.
Remote Validation Guard: this guard is set up to run the validator remotely and we do this by setting the
use_localflag to be False and setting our validation endpoint.
The code for all of these benchmarks can be found in the benchmarks directory of each validator repo (ToxicLanguage and CompetitorCheck).