How it Works
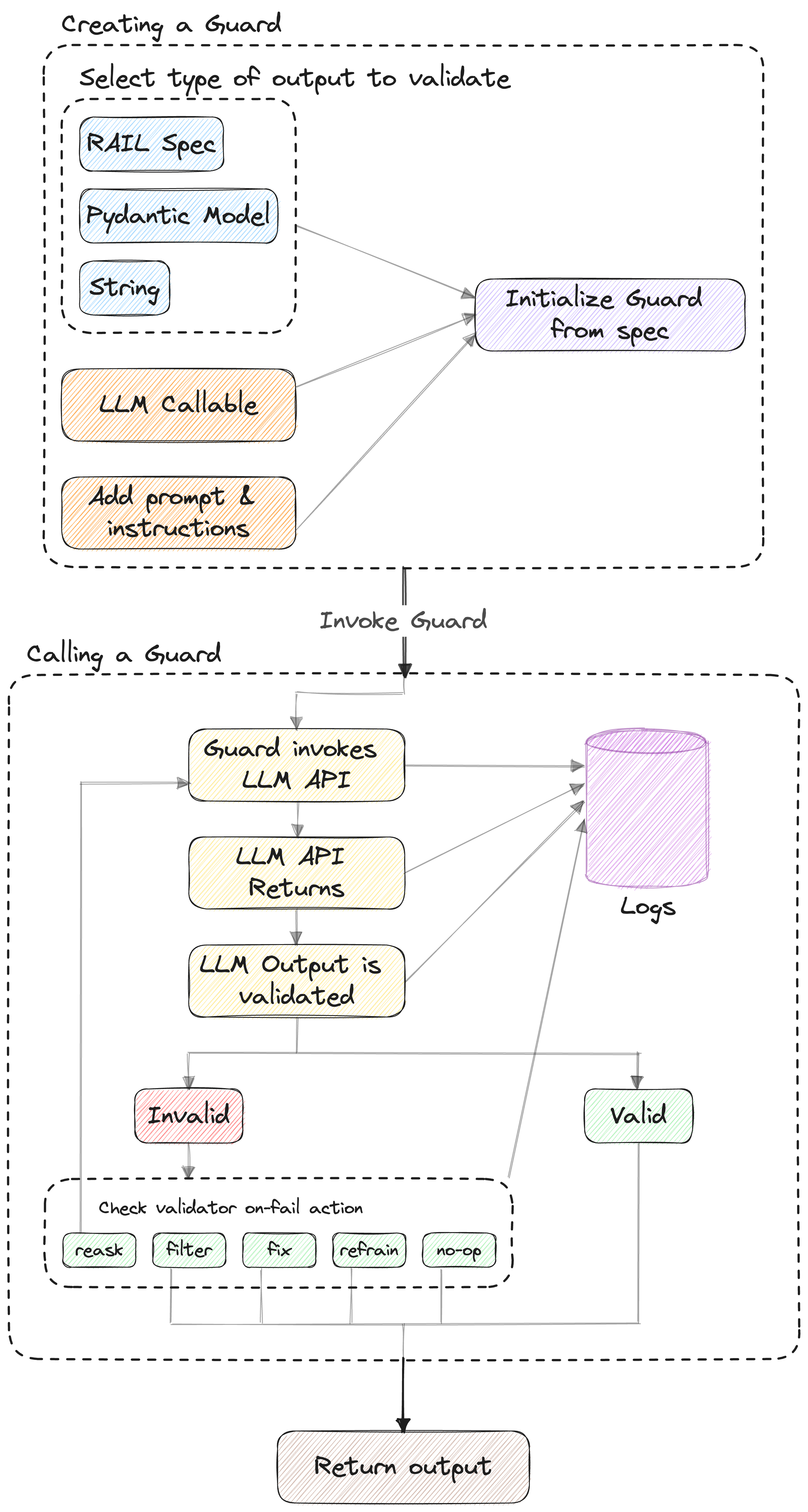
Two main flows
Call
After initializing a guard, you can invoke it using a model name and messages for your prompt, similarly to how you would invoke a regular call to an LLM SDK. Guardrails will call the LLM and then validate the output against the guardrails you’ve configured. The output will be returned as aGuardResponse object, which contains the raw LLM output, the validated output, and whether or not validation was successful.
parse
If you would rather call the LLM yourself, or at least make the first call yourself, you can useGuard.parse to apply your RAIL specification to the LLM output as a post process. You can also allow Guardrails to make re-asks to the LLM by specifying the num_reasks argument, or keep it purely as a post-processor by setting it to zero. Guard.parse returns the same fields as __call__.
Calling Guard.parse as a post-processor:
Guard.parse with reasks: