Guard calls are logged internally, and can be accessed via the guard history.
Whenever Guard.__call__ or Guard.parse is called, a new Call entry is added to a stack in sequence of execution. This Call stack can be accessed through Guard.history.
Calls can be further decomposed into a stack of Iteration objects. These are stateless and represent the interactions within a Call between llms, validators, inputs and outputs. The Iteration stack can be accessed through call.iterations.
General Access
Given:my_guard.history’s first Call entry will represent the guard execution corresponding to response_1 and the second will correspond to response_2’s execution.
To pretty print logs for the latest call, run:
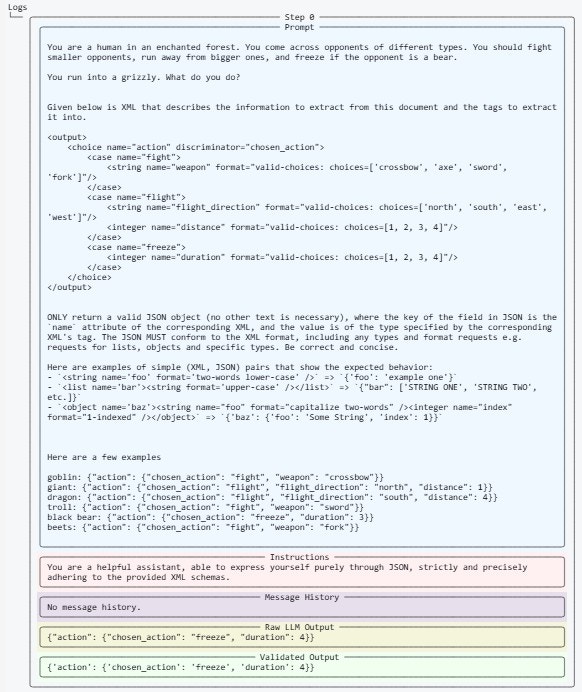
Calls
Initial Input
Initial inputs like messages from a call are available on each call.Final Output
Final output of call is accessible on a call.Cumulative Raw LLM outputs
Call log also the raw returns of llms before validation
Cumulative Token usage
Call log also tracks llm token usage (*currently only for OpenAI models)
Iterations
Validator logs
Detailed validator logs including outcomes and error spans can be accessed on interations.iteration.failed_validations
Raw LLM output
If multiple llm calls are made like in the case of the reask. Iterations contain the return of each call to an llm.Token Usage
Token usage on a per step basis can be accessed on an Iteration.Call, see the History & Logs page. For more information on the properties available on Iteration, see the History & Logs page.