Setup
Install and import the necessary validators1. For structured JSON output
Define the prompt and output schema
Create the Guard object
Example 1: No streaming
By default, thestream parameter is set to False
warnings.warn(

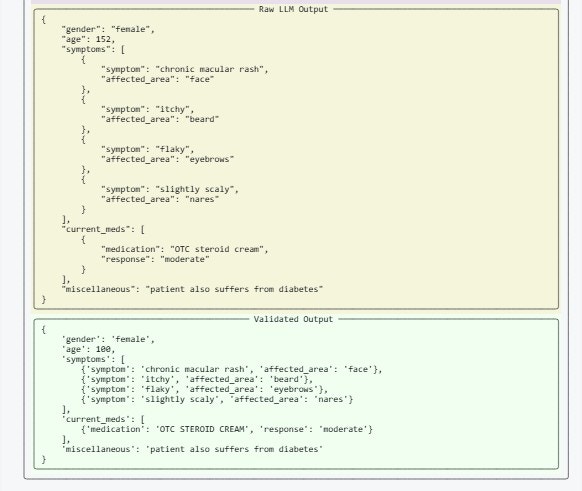
Example 2: Streaming
Set thestream parameter to True
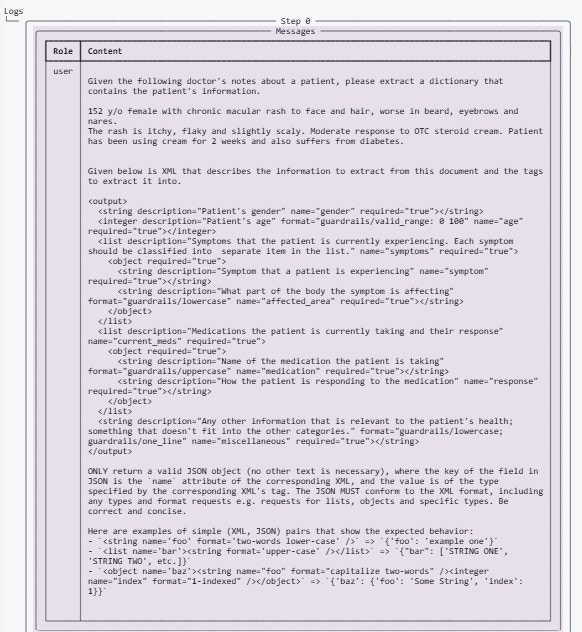
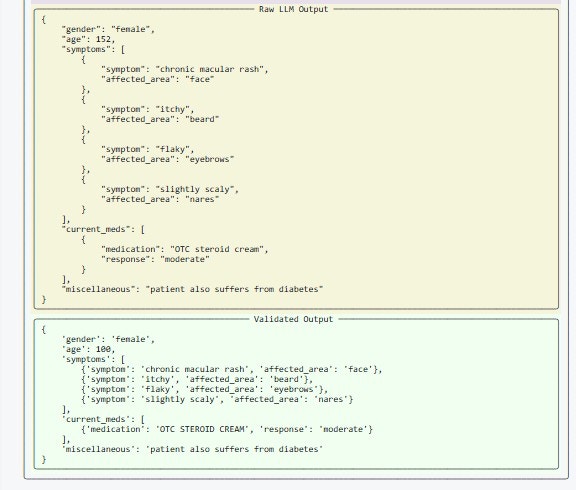
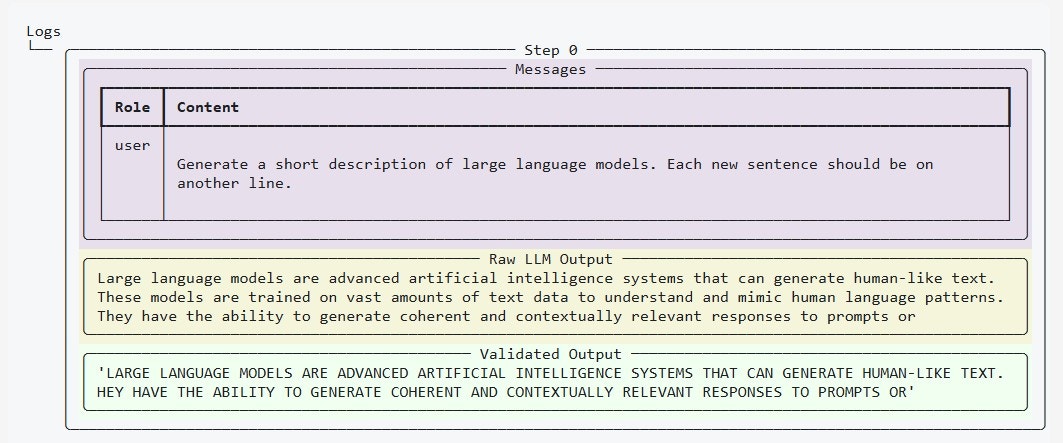
2. For unstructured text output
Define the prompt and Guard object with validators
Example 1: No streaming
By default, thestream parameter is set to False
warnings.warn(
Example 2: With streaming
Set thestream parameter to True