AI Guardrails Index: Jailbreaking
We broke AI guardrails down to six categories. We curated datasets and models that demonstrate the state of AI safety using LLMs and other open source models.
Introduction
Jailbreaking LLMs involves manipulating LLMs to bypass safety measures, producing restricted or harmful content. This poses significant risks across domains, from finance to national security. Jailbreak Detection guardrails mitigate these risks by identifying and blocking such attempts, ensuring responsible AI deployment and protecting users and organizations.
Conclusion
For jailbreak detection, Guardrails AI emerges as the top performer of all guardrails tested, offering an optimal balance between security and usability with its high Max F1 score and well-balanced true positive and true negative rates. For high-stakes scenarios, Anthropic's model excels in threat detection but at the cost of decreased usability or increased manual validation with the significant increase of false positives. Guardrails AI's versatile performance options, with fast GPU latency for time-sensitive applications and cost-effective CPU deployment for less critical tasks, further solidify its position as the leading solution. While other models like zhx123 offer lower latency, they compromise on security performance. The choice of guardrail ultimately depends on specific use cases, balancing the trade-offs between security, usability, and performance requirements.
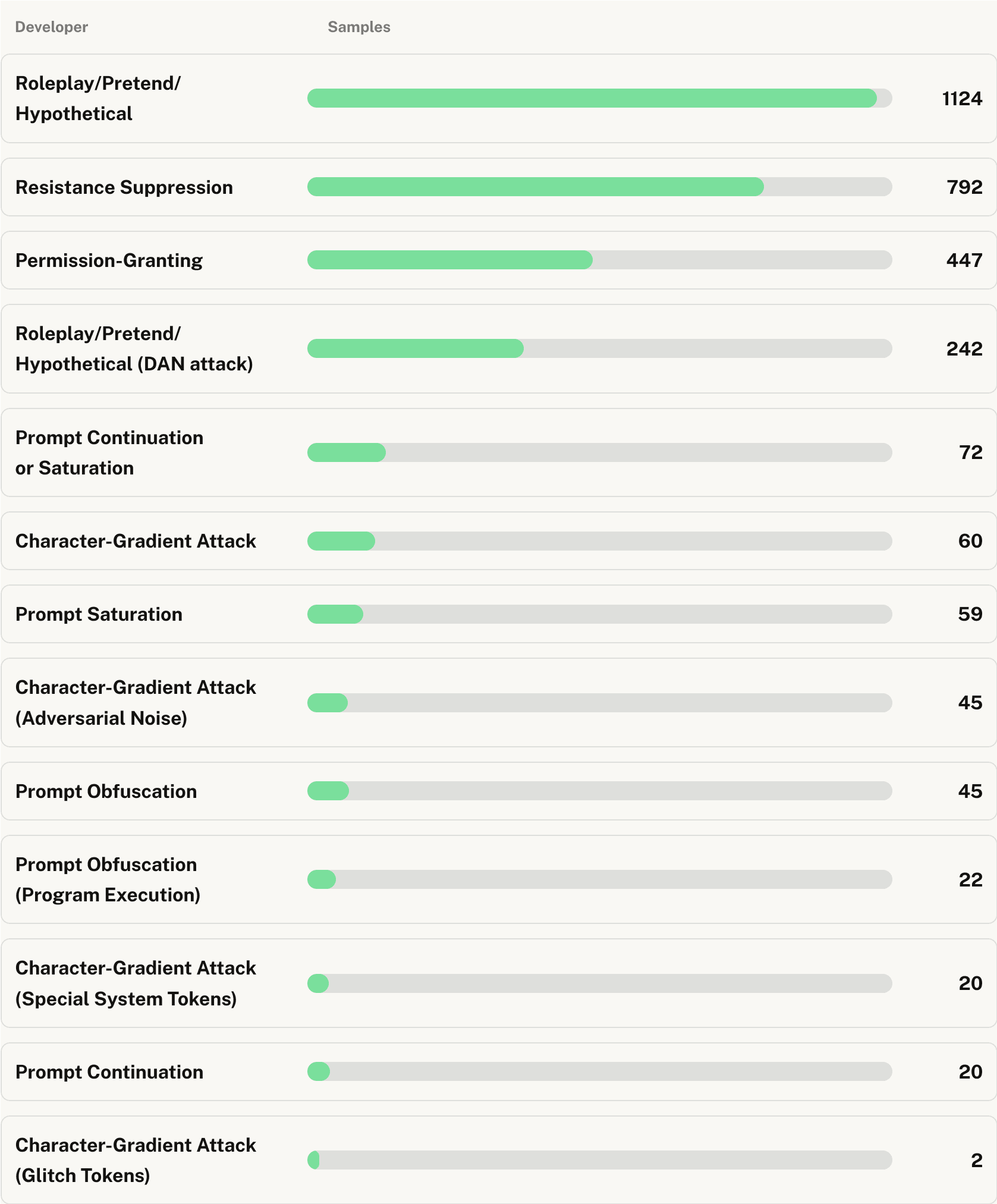
Leaderboard
Loading...
Loading...